Iterative Server
Iterative Server는 하나의 process만을 사용하는 Server이다.
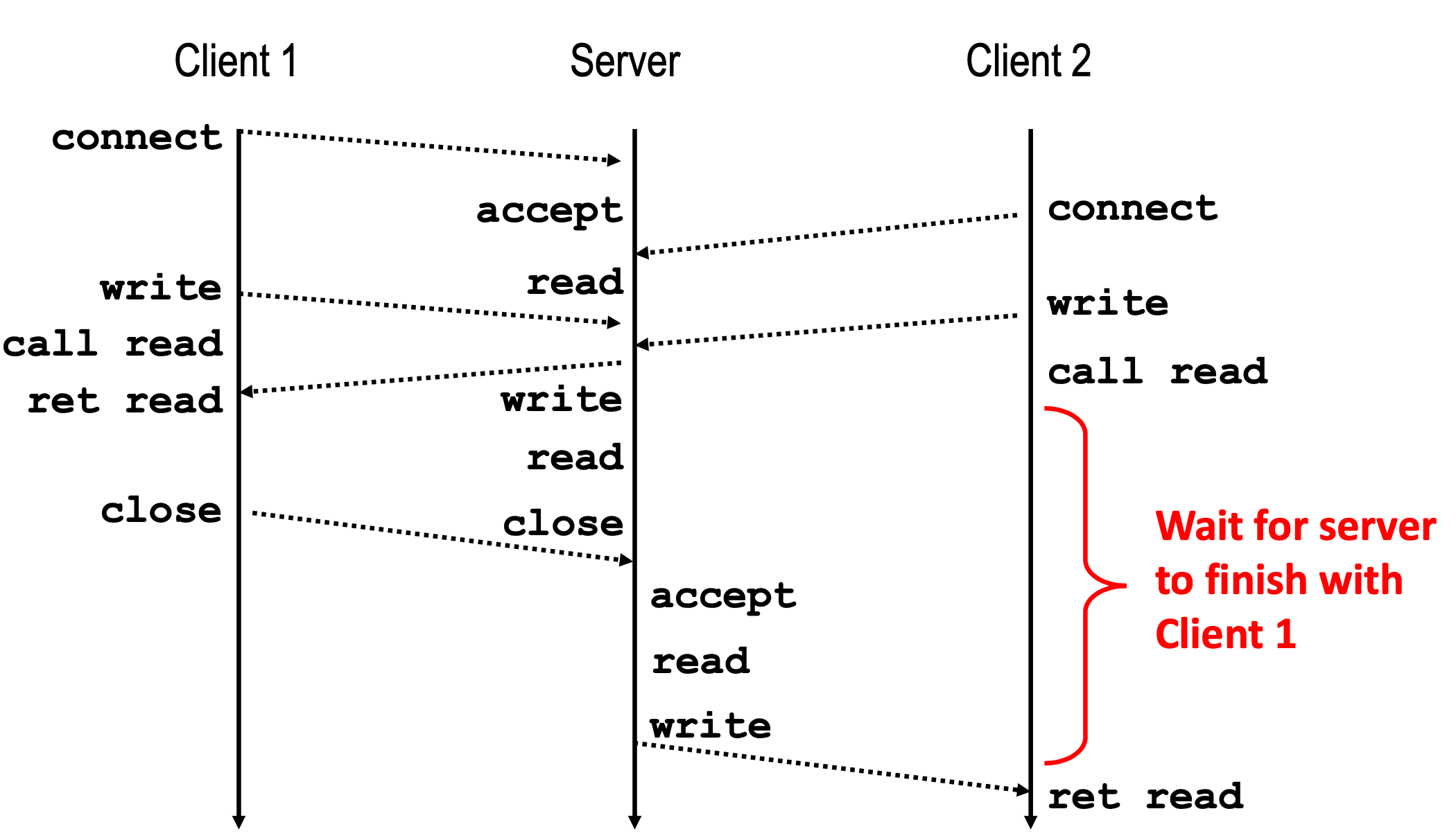
Iterative Server에서 client의 connection이 먼저 생성되면 그 connection이 종료될 때까지 다른 client에게 service를 제공하지 못한다. 따라서 client가 server를 무한정 기다리게 되는 상황이 발생한다.
Connect 함수는 connection이 생성되지 않았더라도 server의 listenfd에 queuing되면 리턴 값을 반환하기 때문에 client는 read를 하면서 block된다.
Process-based Server

Process-based Server는 여러 개의 process를 사용한다.
Client와의 connection이 생길 때마다 child process가 생성되어 이를 관리한다.
Connection마다 process가 할당되기 때문에 concurrent하게 service를 제공할 수 있다.
※주의해야 할 점은 connection을 없앨 때, parent process는 connfd를 child process는 listenfd를 반드시 close 해야 된다.(메모리 누수 방지)
장점
- concurrent하게 connection 가능
- Sharing model이 간단하다.(Process들끼리는 data를 공유하지 않음)
- 간단하고 직관적이다.
단점
- 여러 개의 process를 fork하는데 overhead가 발생한다.
- Process끼리 data를 주고 받지 못한다.
Event-based Servers
Event-based Server는 하나의 process를 사용한다.
대신 I/O multiplex를 사용하여 concurrent하게 service를 제공할 수 있다.
Server는 connfd와 listenfd가 있는 배열을 가지고 있다.
Event-based Server logic
- 배열을 돌면서 어떤 descriptor가 pending bit를 가지고 있는지 확인한다.
- 먼저 listenfd에 input이 있다면 그 request들을 accept해준다.
- pending bit가 있던 connfd에 대해서 service를 제공한다.
※예시

위는 listenfd와 connfd[1], connfd[5], connfd[6]에 pending bit가 있는 경우이다. pending bit는 항상 Active된 file descriptor에만 존재 할 수 있다.
장점
- 한 개의 logical control과 address space를 이용한다.
- 간단히 debugging을 할 수 있다.
- 한 개의 process만을 사용하므로 overhead가 발생하지 않는다.
단점
- 다른 server에 비해 코드 짜는 것이 어렵다.
- fine-grained concurrency를 제공하기 어렵다.
- Multi-core가 있더라도 사용하지 못한다.
어떻게 single process로 concurrent하게 실행 될 수 있을까?
Iterative server는 server가 client에게 input이 올 때까지 무작정 기다리고 있지만 Event-based server는 정해진 시간만큼만 기다리고 다음 event를 처리하러 간다. 간단히 이야기하자면 모든 event들은 정해진 시간만큼만 돌아가고 차례를 기다리게 된다.
Thread-based Server
운영체제 시간에 Thread의 개념을 이해하려고 노력했는데 처음 접하는 개념이다 보니 이해하기가 어려웠다.
지금은 나름 개념을 이해한 것 같다. 내가 이해한 Thread의 개념은 다음과 같다.
사람들은 컴퓨터가 여러 가지 일들을 효율적으로 하기 위해 Process라는 개념을 만들었다. 여기서 여러가지 일들이란 서로 관련이 없는 다른 일들을 의미한다. 그래서 Process끼리는 data를 공유하지 않는다.
사람들이 Thread라는 개념을 만든 이유는 한 가지일을 효율적으로 하기 위함이다. 즉, Process가 할당 받은 일을 여러 개의 Thread가 동시에 하게 된다. 따라서, Thread끼리는 code와 data를 공유한다.
위 개념을 가지고 Process = thread + code,data and kernel context를 생각해보면 좋을 것 같다.

Thread 특징
- 각각의 thread는 고유의 logical flow를 갖는다.
- 각각의 thread는 같은 code, data, kernel context를 가진다.
- 각각의 thread는 지역 변수에 대한 고유의 stack을 갖는다.
- 각각의 thread는 thread id(TID)를 갖는다.
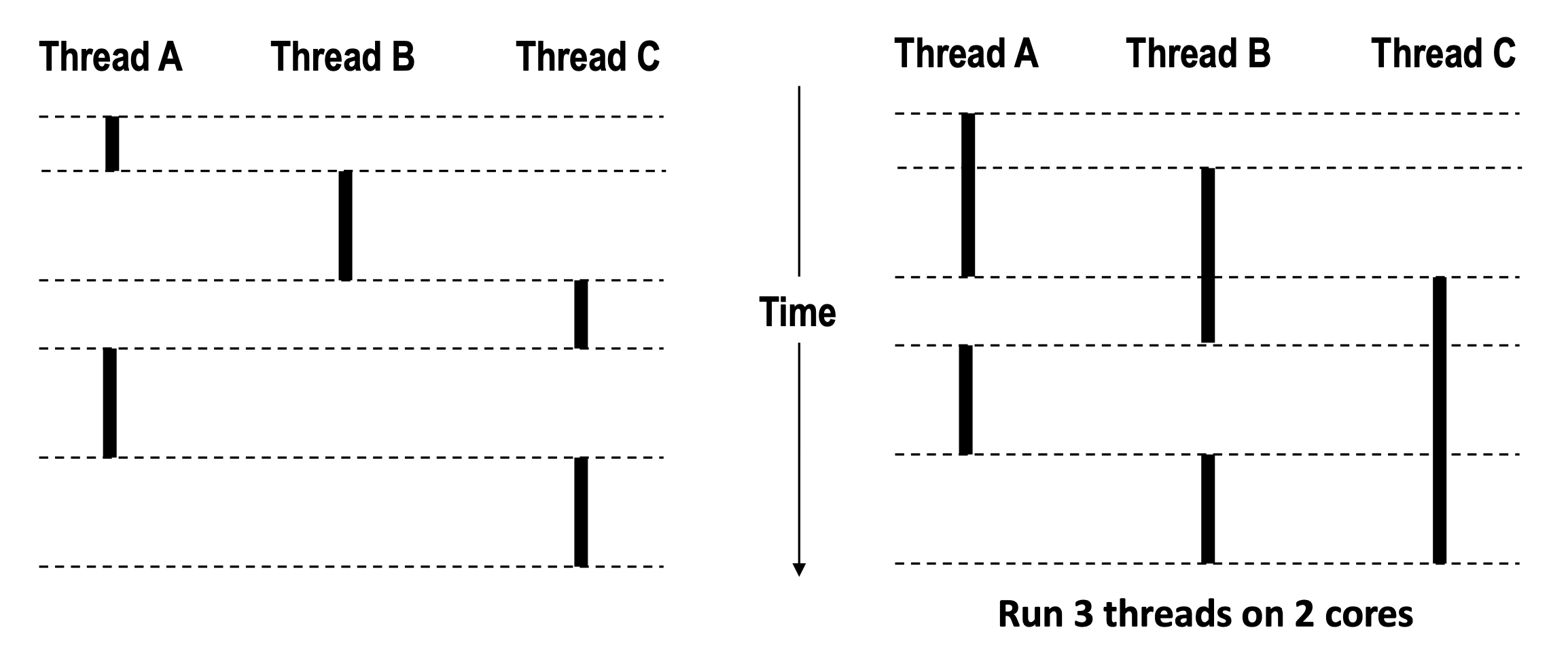
왼쪽은 Single Core Processor이고 오른쪽은 Multi- Core Processor이다.
Multi-Core를 이용하면 동시에 여러 개의 Thread의 작업을 할 수 있다.
주의해야 할 점
- detached를 사용하여 메모리 누수를 막아야 한다. Joinable thread는 다른 thread에 의해 kill 될 수 있지만 Detached thread는 그렇지 않다. 하지만 제거되면서 자동적으로 제거된다.
- Thread끼리는 data를 공유하기 때문에 unintended sharing이 일어나는 것을 막고 항상 thread-safe한 함수를 사용해야 한다.
장점
- Thread들 끼리 data를 주고받기 쉽다.
- Thread는 data를 공유하므로 만드는데 process보다 적은 비용이 든다. 따라서 Process보다 효율적이다.
단점
- Unintentional sharing은 error를 발생시키고 이를 해결하기가 어렵다.
'4-1 > 시스템프로그래밍' 카테고리의 다른 글
| Network Programming (0) | 2022.04.05 |
|---|---|
| Standard I/O, Unix I/O vs Standard I/O vs RIO (0) | 2022.04.04 |
| Metadata, sharing and redirection (0) | 2022.04.04 |
| Unix I/O, RIO package (0) | 2022.04.04 |
| Signal (0) | 2022.03.28 |