CLR parsing
- SLR 방법보다 강력하다는 장점
- lookahead를 구하는 과정이 복잡하고 시간이 오래 걸리며 parse table이 크다는 단점
LALR(Look ahead LR) parsing
- LR(1)과 같이 reduce action에서는 lookahead를 이용
- Parsing table의 크기를 되도록 작게 구성
Strengths
- SLR 방법보다 강력
- parse table의 크기가 CLR 방법보다 작음
- 프로그래밍 언어의 구문 구조를 대부분 편리하게 표현할 수 있음
- 모호하지 않은 문맥자유 문법으로 표현된 거의 모든 언어를 인식
- 에러를 초기에 탐지 가능
Weaknesses
- parse table을 만들기 위해 lookahead 기호를 구하는 것이 어려움
LALR Parser Implementation
- 파싱표를 구성하기가 쉽지만 파싱표의 크기가 커지는 LR(1)을 가지고 구성
- 같은 코어를 가진 LR(1) item을 묶어서 하나의 state로 구성
- 효율적으로 파싱표를 구성할 수 있는 LR(0)과 lookahead를 가지고 구성
- LR(1) item의 lookahead를 합한 것으로 구성

I36, I47, I89 라는 state를 만든다( 같은 코어를 가진 LR(1) item을 묶어서 하나의 state로 만든 것 )
| State | Action | GOTO | |||
| c | d | $ | S | C | |
| 0 | s36 | s47 | |||
| 1 | acc | ||||
| 2 | s36 | s47 | 5 | ||
| 36 | s36 | s47 | 89 | ||
| 47 | r3 | r3 | |||
| 5 | r1 | ||||
| 89 | r2 | r2 | r2 | ||
LR(1) item set으로 부터 작성
- 이론적으로 쉽게 설명
- 하지만 C1의 크기가 너무 커져서 비효율적
- Lookahead에 따라 state의 수가 매우 커지고 시간이 오래 걸리기 때문
LR(0) item set으로 부터 작성
- 이론적으로 복잡하고 어려움
- 하지만 시간적, 공간적으로 효율적임
LR(0) item set으로 부터 작성하는 방법
- LR(0) item set의 canonicla collection C0를 구성 (SLR과 동일)
- Parse table의 shift, accept, GOTO action을 구성 (SLR과 동일)
- Reduce action은 lookahead에 의해 결정 (LALR)
따라서, lookahead를 구하는 것이 핵심이다.
PRED
PRED를 쉽게 설명하자면
GOTO(I0,d) = I4
GOTO(I3,d) = I4
일 때, PRED(I4,d) = {I0,I3} 라는 뜻이다.
Lookahead
Note : 𝛾ɑ accesses p : 시작 상태로부터 𝛾ɑ만큼 보고 state p로 이동을 하였다는 의미


솔직히 무슨 말인지 모르겠다. 문제를 풀면서 이해하자.
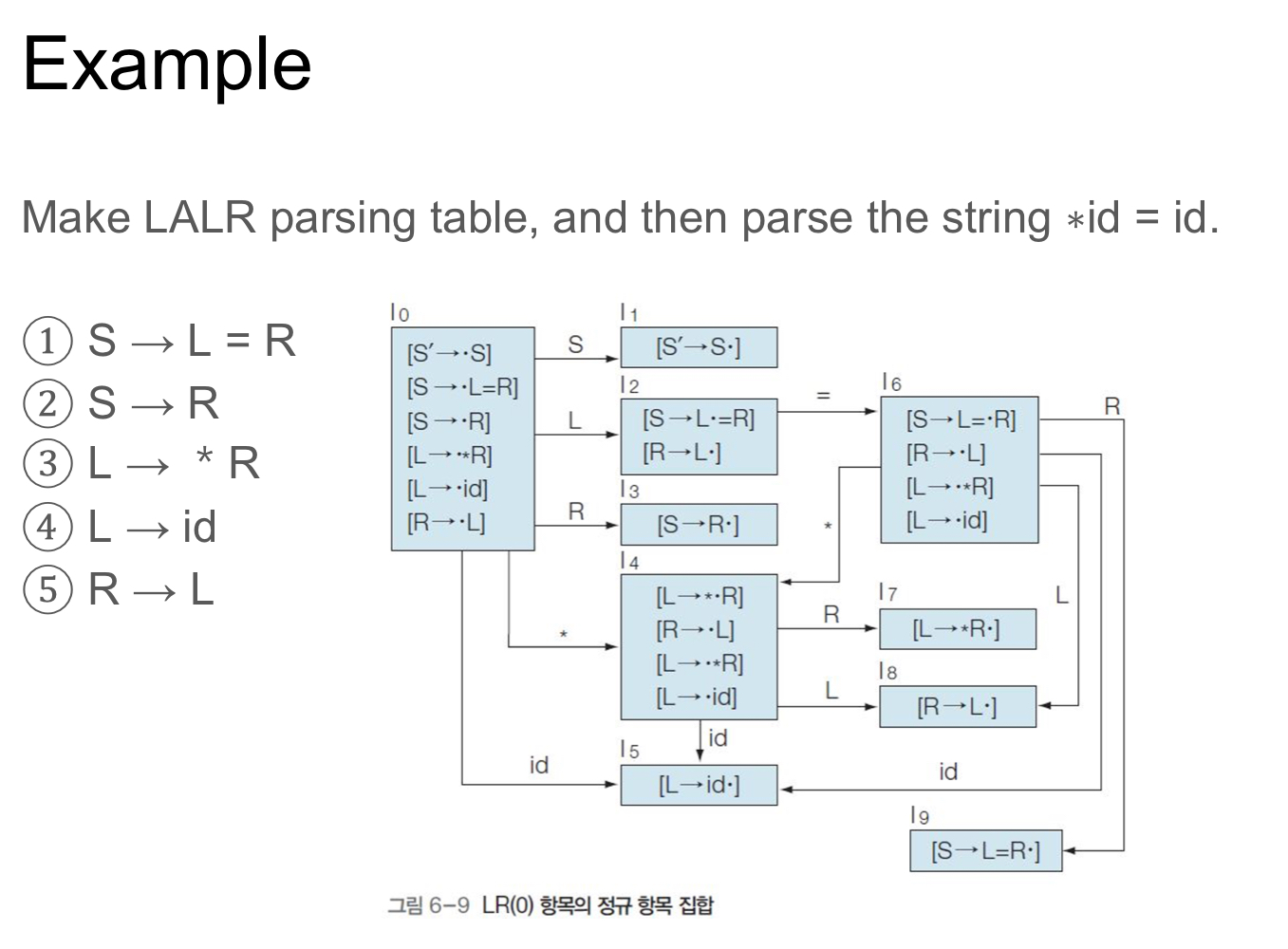




위를 바탕으로 LALR 파싱표를 만들어보자
| State | Action | GOTO | |||||
| = | * | id | $ | S | R | L | |
| 0 | s4 | s5 | 1 | 3 | 2 | ||
| 1 | acc | ||||||
| 2 | s6 | r5 | |||||
| 3 | r2 | ||||||
| 4 | s4 | s5 | 7 | 8 | |||
| 5 | r4 | r4 | |||||
| 6 | s4 | s5 | 9 | 8 | |||
| 7 | r3 | r3 | |||||
| 8 | r5 | r5 | |||||
| 9 | r1 | ||||||
Ambiguous Grammar
여태 LR parser는 unambiguous grammar만 다루었다.
Ambiguous grammar
- derivation 방식에 따라서 2개 이상의 파스 트리를 만들 수 있음
- 모든 ambiguous grammar는 LR grammar가 아님
Strengths
- ambiguous grammar는 언어의 specification을 제공할 때 유용하다
- 언어 구조에 대해 ambiguous grammar는 더 짧고 자연스러운 specification을 제공한다
Weaknesses
- Non-deterministic parsing
- Parse table을 작성할 때 항상 shift-reduce 충돌이나 reduce-reduce 충돌을 야기한다

- Production rule의 우선순위는 해당 rule에 포함된 terminal symbol로 결정
- Shift-reduce conflict일 경우
- Production rule의 우선순위가 높으면 reduce, 그렇지 않으면 shift
- 같을 경우, Left associativity면 reduce, right associativity면 shift
- Reduce-reduce conflict
- Production rule들간의 우선 순위를 비교하고, 높은 것을 선택하여 reduce
- 같을 경우, Left associativity면 reduce, right associativity면 shift
I7 = { [E->E+E·] , [E->E·+E] , [E->E·*E] }
I8 = { [E->E*E·] , [E->E·+E] , [E->E·*E] }
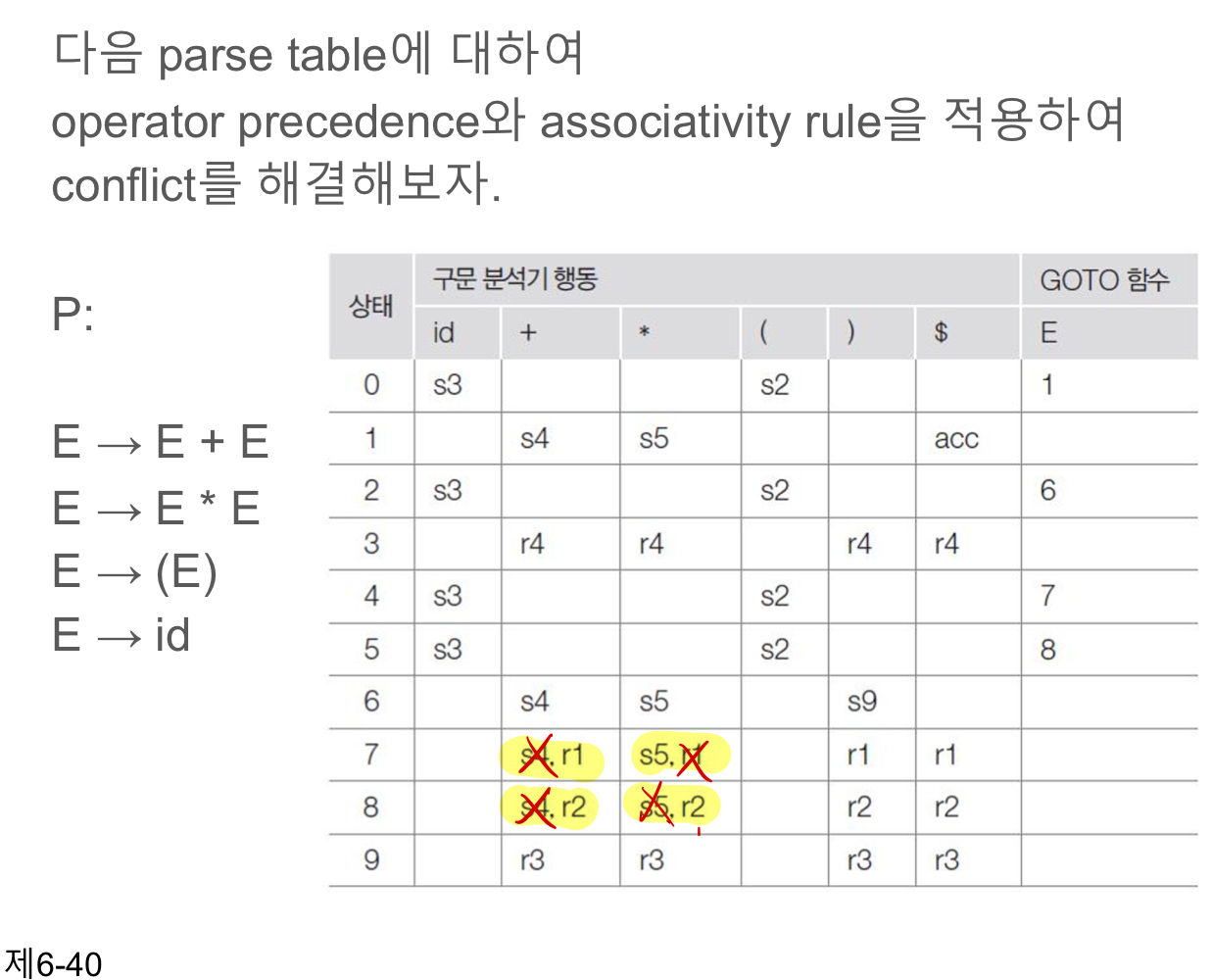
- Unambiguous grammar에 대해서는 28단계의 parsing과정을 거친다.
- Ambiguous grammar + Operator precedence/associativity rule은 16단계의 과정을 거친다.
따라서 Unambiguous grammar라고 하여도 conflict를 잘 해결할 수 있다면 더욱 효율적으로 parsing이 가능하다.
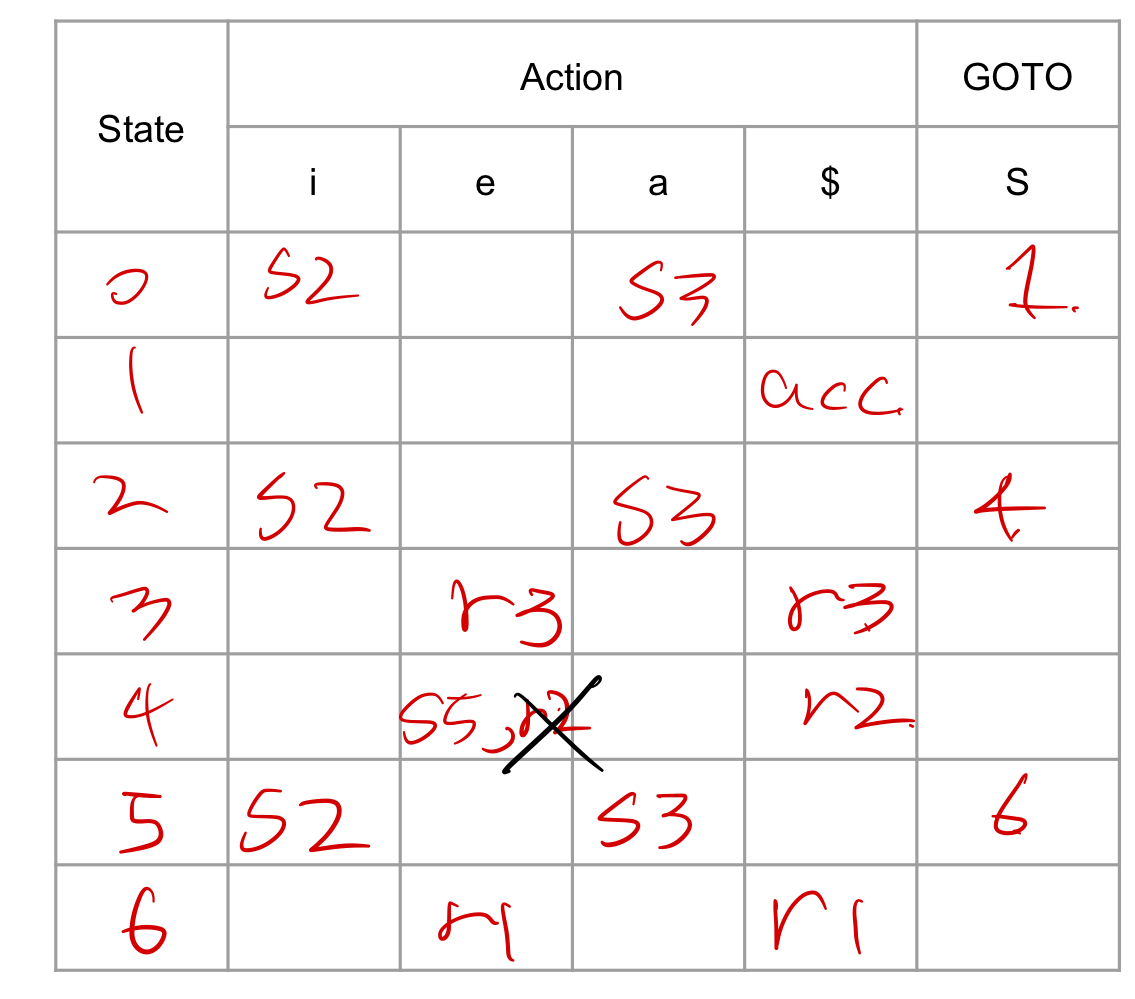
충돌을 해결을 해결하고 iiaea의 파싱을 해보자.
가정 : else는 항상 가장 가까운 if에 걸림
I4 = {iS·eS,iS·} 라고 할 때, s5와 r2가 충돌하는데 else는 가장 가까운 if에 걸리므로 r2를 제거한다.
'3-2 > 기초컴파일러' 카테고리의 다른 글
| CLR parser (0) | 2021.11.07 |
|---|---|
| Bottom-up parsing (0) | 2021.11.06 |
| Recursive-decent, Predictive Parsing (0) | 2021.10.16 |
| Syntax Analysis (0) | 2021.10.16 |
| Pushdown Automata (0) | 2021.10.16 |