Lexical Analysis

소스 프로그램을 token 단위로 분리하여 토큰 스트림을 출력한다.
Token
Token은 터미널 기호들로 구성된 문법적으로 의미 있는 최소 단위이다.
Special form - language designer
- 예약어(Reserved word) : for, if, int 등의 언어에 이미 정의된 단어
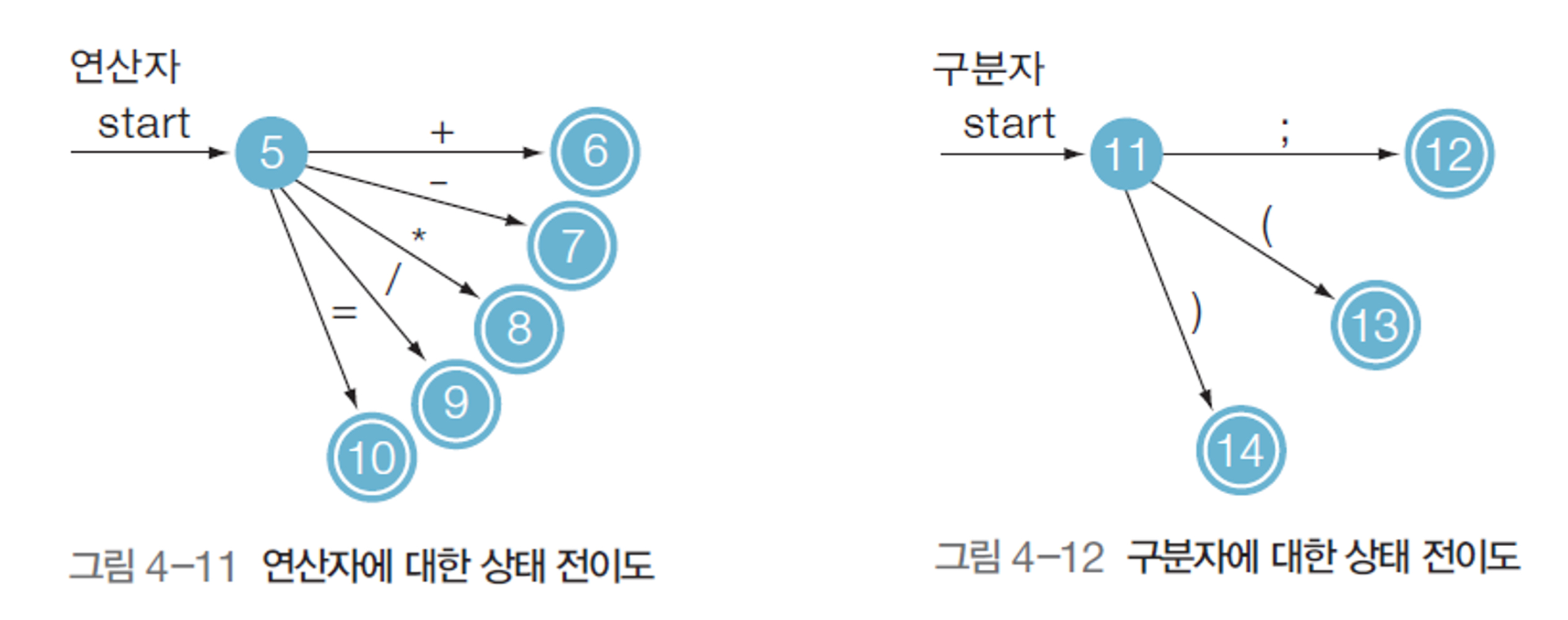
- 연산자(operator) : +,-,*,/,<,=,++ 등의 연산기호
- 구분자(Delimiter) : ;, , ,(,),[,] 등 단어와 단어를 구분하거나 문장과 문장들을 구분하는 기호
General form
- 식별자(Identifier) : abc,b12,sum 등 프로그래머가 정의하는 변수
- 상수(Constant) : 526,3.0,1234e-10,'string' 등 실수형, 정수형, 문자형 상수



Token stream notation
Token stream : 토큰을 token number와 token value의 tuple으로 표현(token number, token value)
- Token number : 각각의 토큰들을 구분하기 위해서 고유의 번호(정수)를 부여
- Token value : 렉심들을 구별하기 위한 값
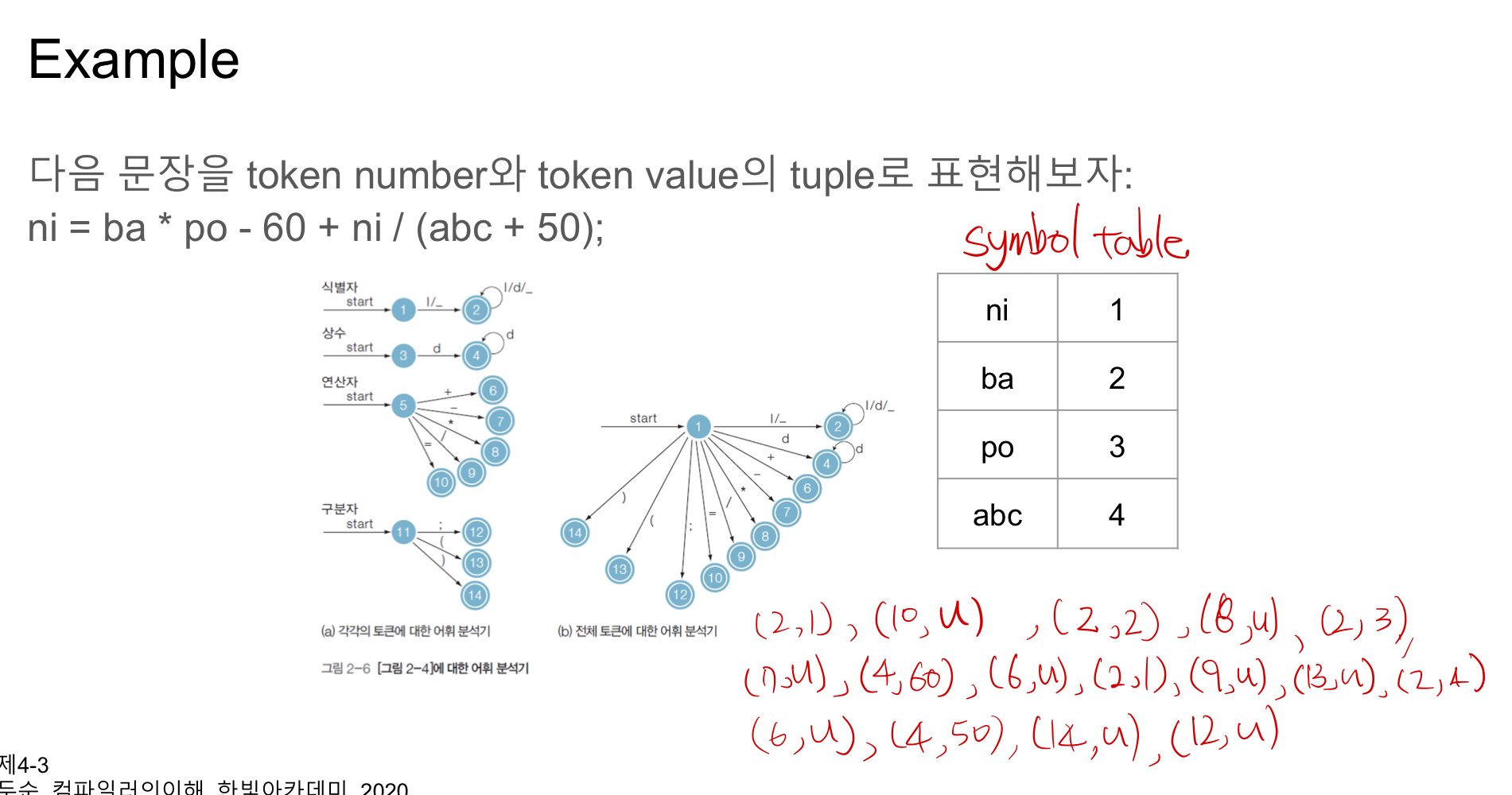
Recognition of Tokens
Recognition : regular expression으로 구성된 토큰을 받아들이는 finite automata이다.
예시:
letter (l) -> a|b|c|....|Y|Z
digit (d) -> 0|1|2|...|9

Recognition of Reserved Words
C에서 예약어를 만드는 방법은 identifier를 만드는 방법과 동일하다.
identifier인지 먼저 검사하고 별도 표에 기록되어 있는 reserved word와 비교한다.
매칭되는 것이 있으면 해당 reserved word를 출력하고 없다면 identifier로 출력한다.

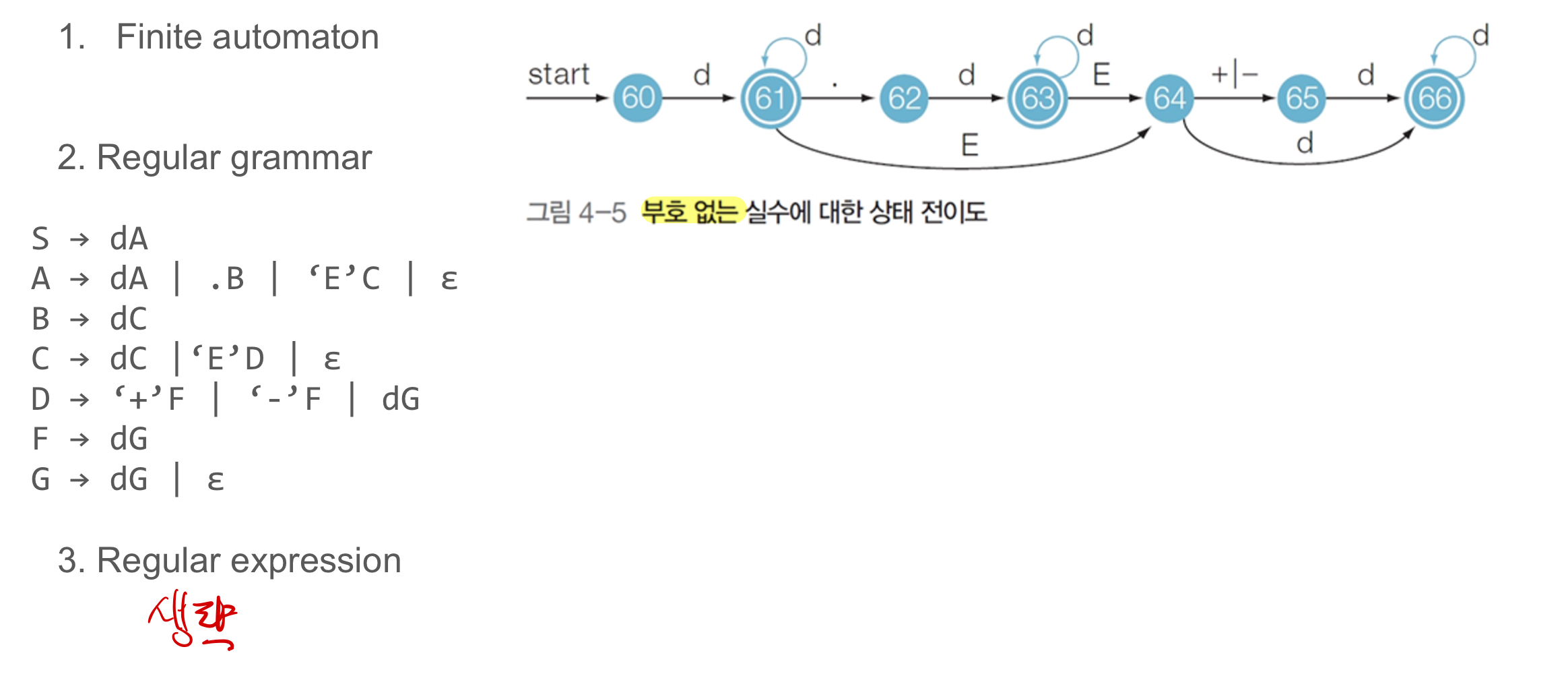
Recognition of Integer and Real number


Implementation of Lexical Analyzer
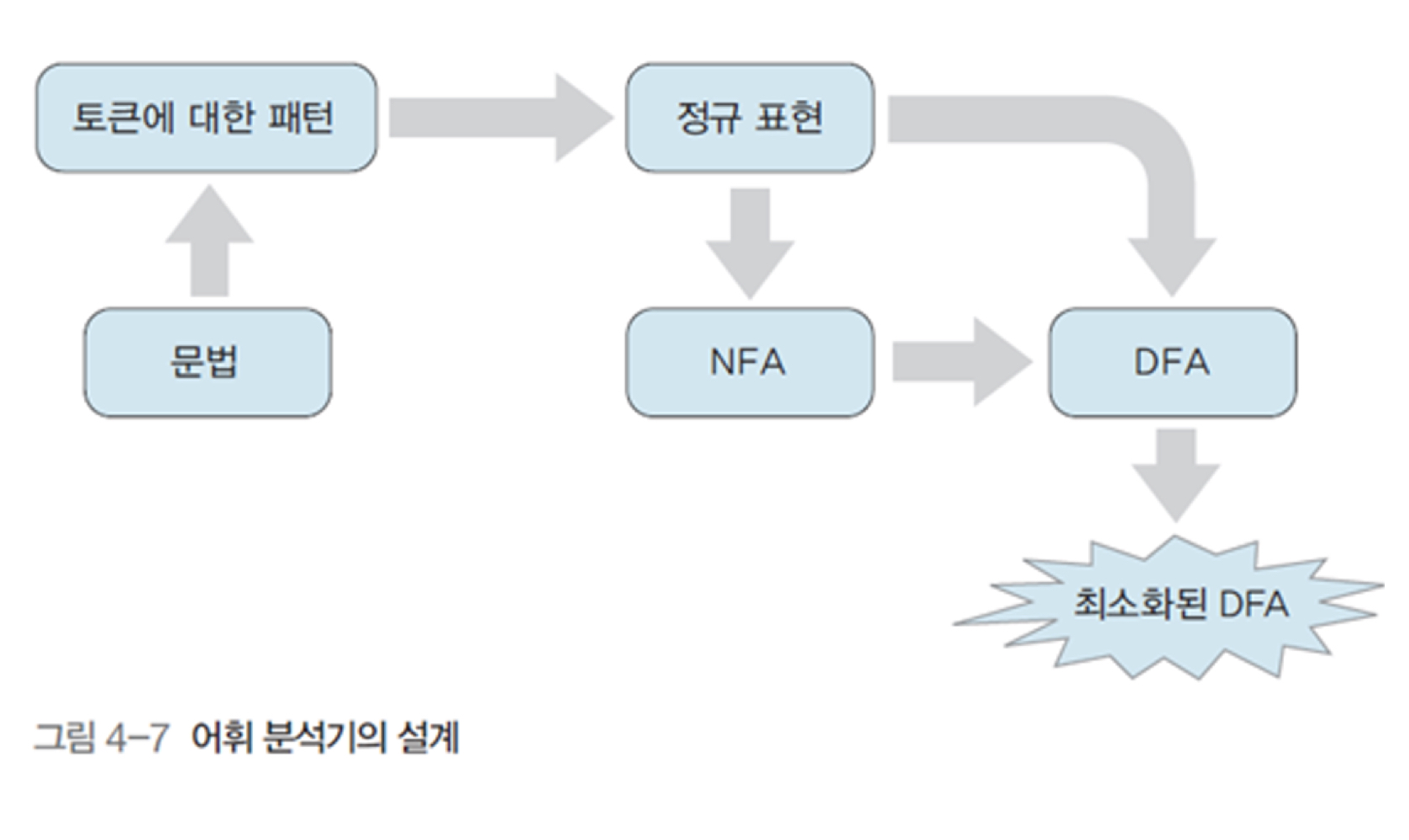
어휘분석기의 구현 방법
- 이론적인 방법들을 프로그래밍을 통하여 구현
- 렉스Lex나 플렉스Flex를 통해서 구문 분석기를 생성하는 방법(chap 13)
프로그래밍 방법 :
1. 문법에서 사용하는 토큰/패턴을 찾아서 토큰표를 만든다.
2. 토큰 표 -> Regular grammar -> Regular expression -> NFA -> DFA -> Minimized DFA

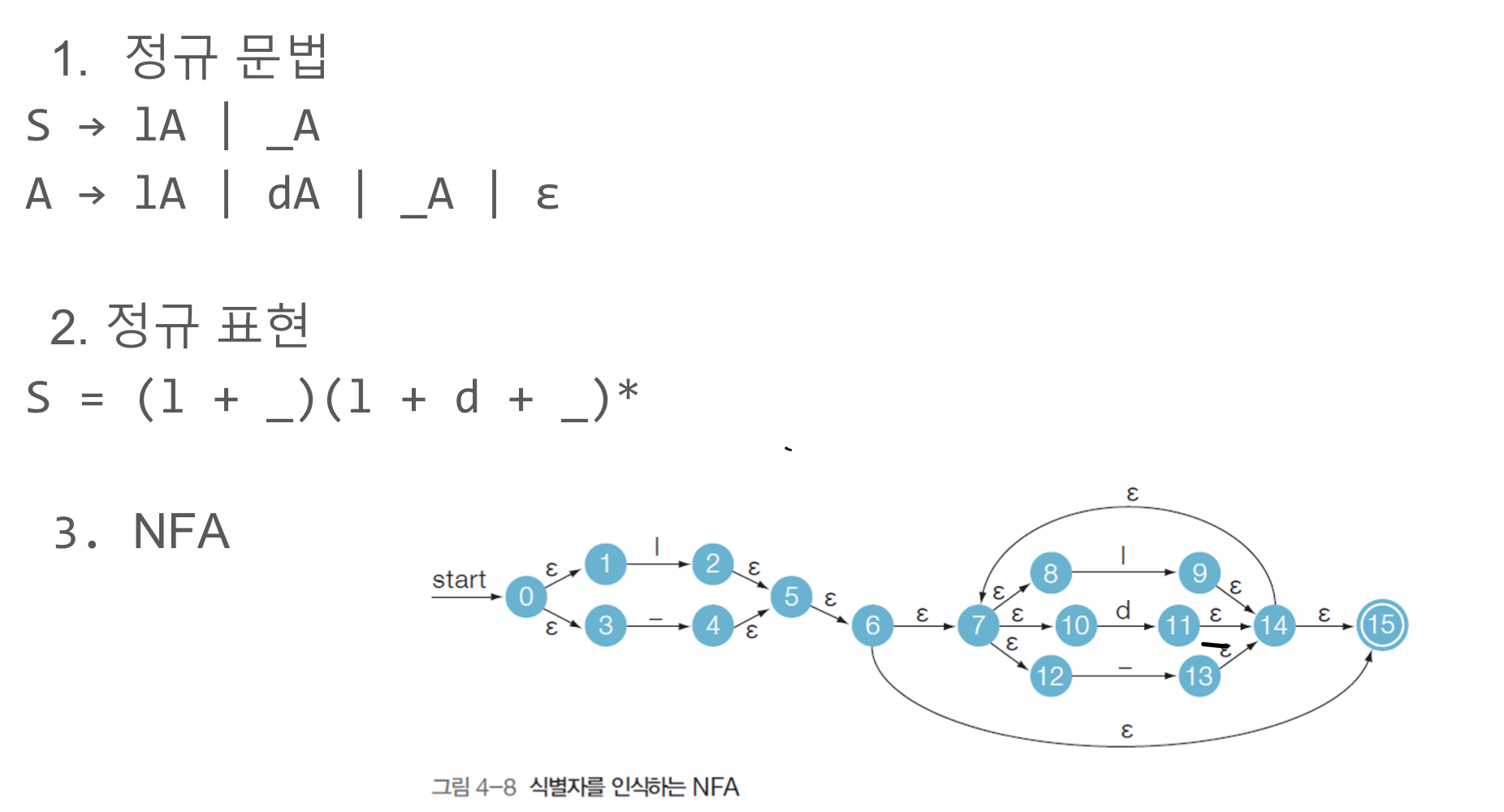
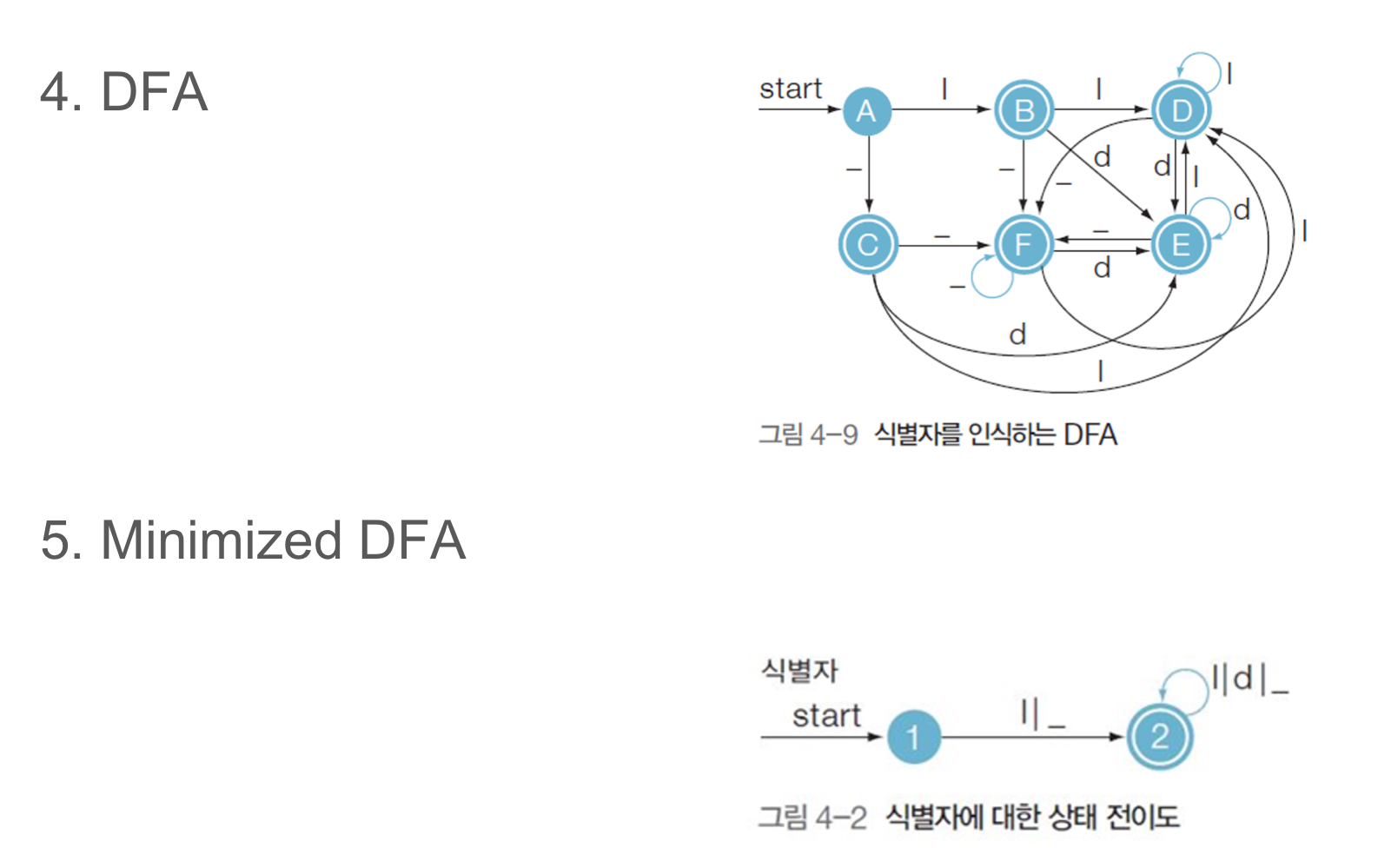
Scanner for identifier
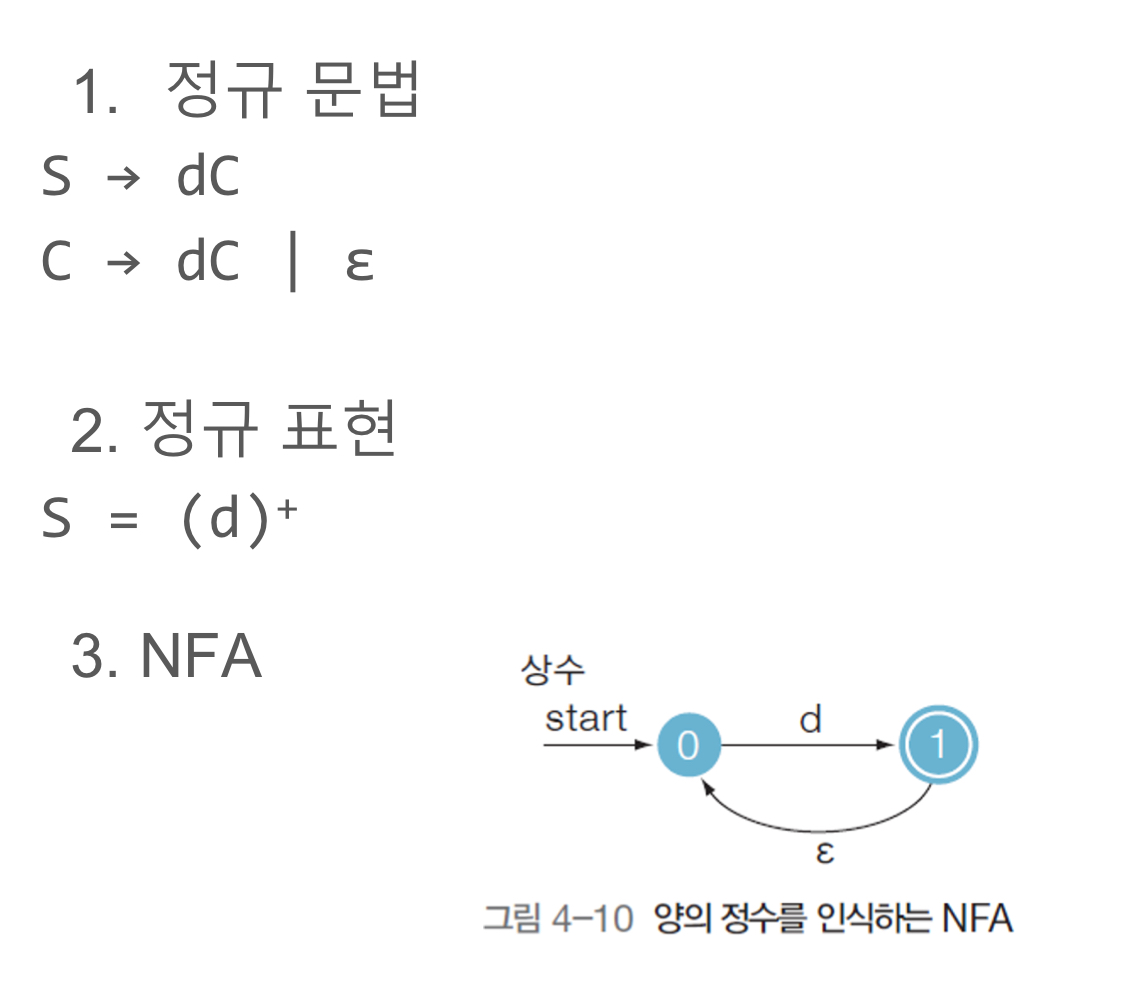
Scanner for constant
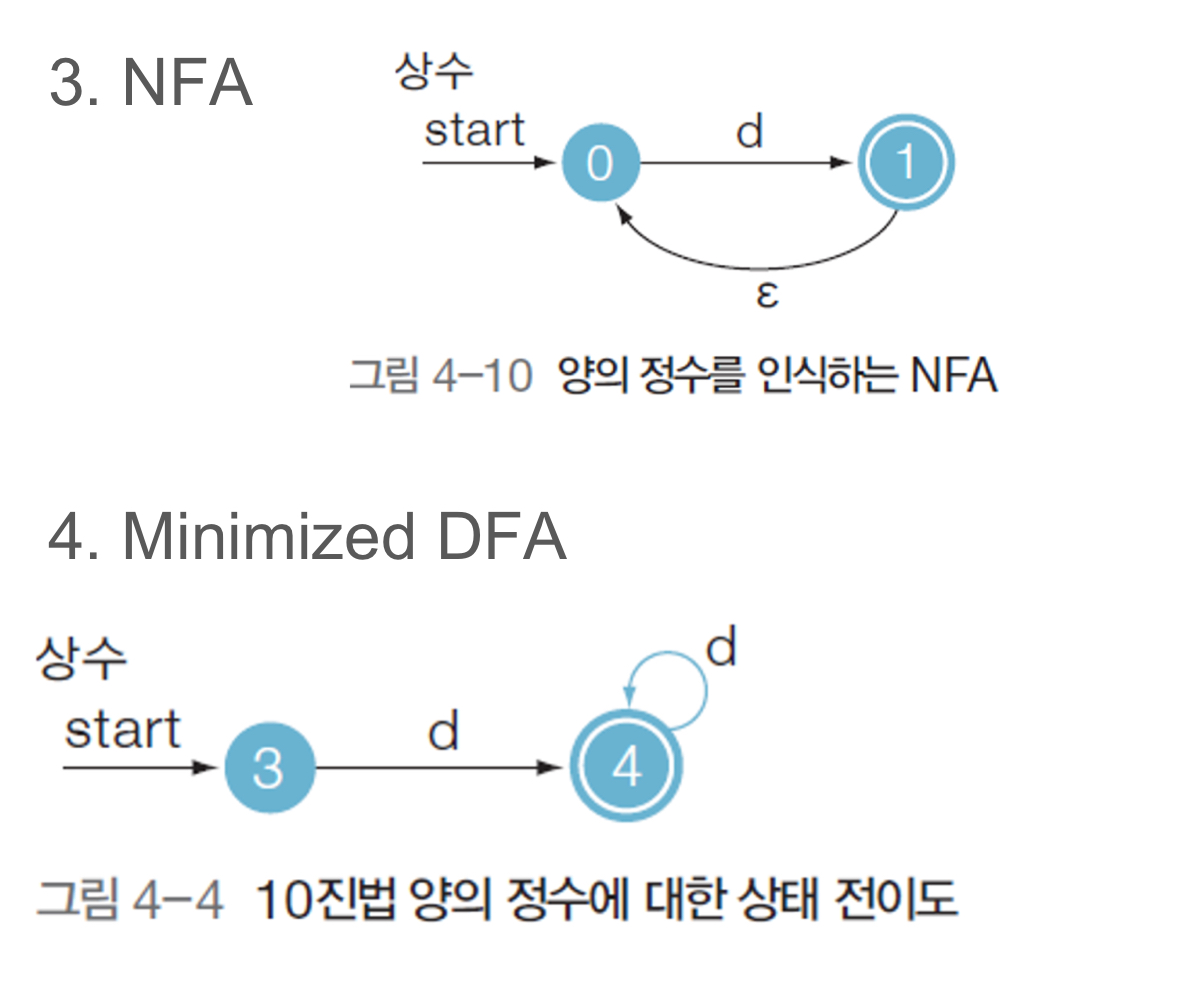
Scanner for Operator and Delimiter
Scanner
'3-2 > 기초컴파일러' 카테고리의 다른 글
| Grammar Conversion (0) | 2021.10.09 |
|---|---|
| Context-free Grammar, Parse Tree, Ambiguous Grammar (0) | 2021.09.30 |
| NFA->DFA, State Minimization (0) | 2021.09.18 |
| Finite Automata (0) | 2021.09.18 |
| Chomsky hierarchy (0) | 2021.09.10 |