컴파일러 구조
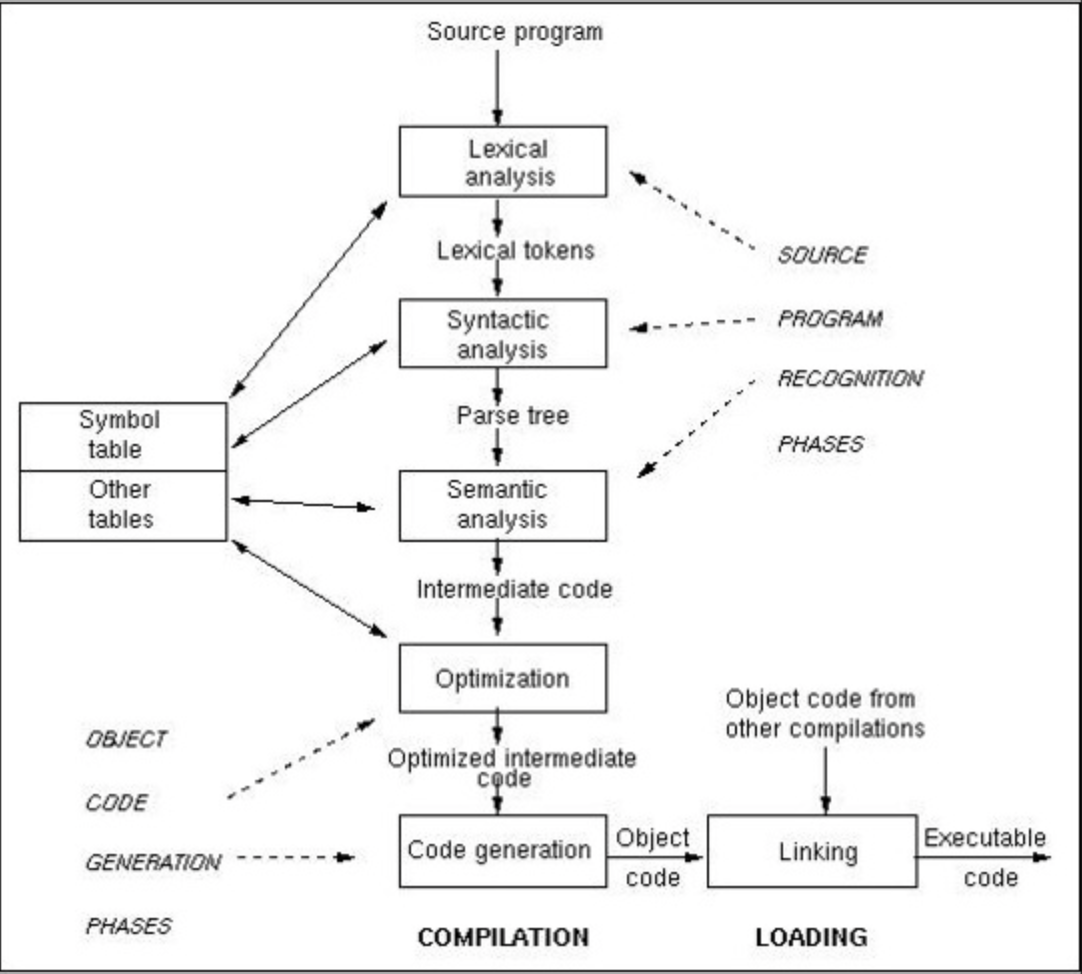
컴파일러는 위와 같은 순서로 돌아간다.
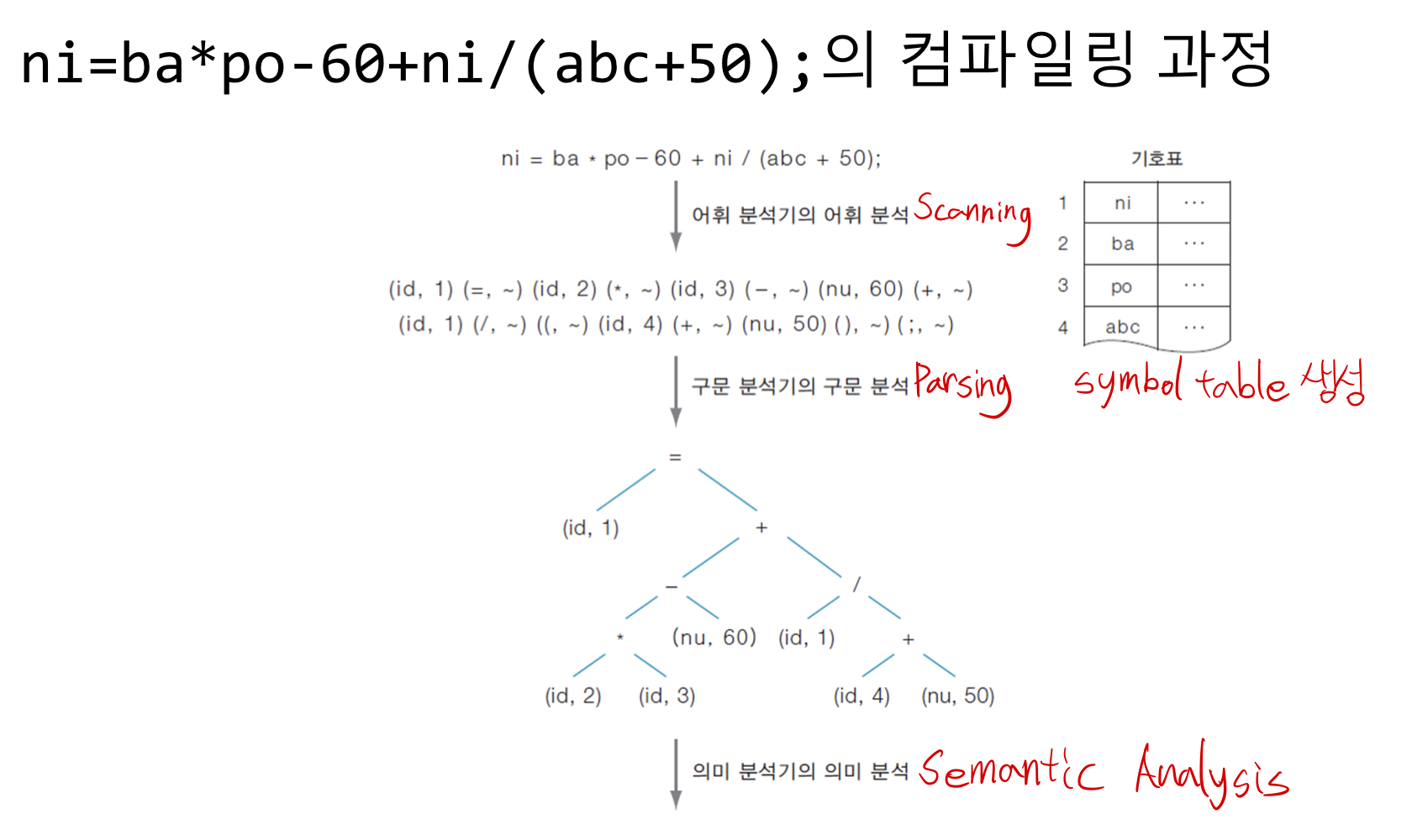
1. Scanning = Lexical Analysis(어휘 분석) - 주어진 문장이 어떤 단어를 포함하고 있는지 확인한다. 가장 작은 의미있는 단어를 'token'이라고 하는데 이를 구분한다.
2. Parsing = Syntax Analysis(구문 분석) - 추출된 token들이 문장의 구성 요소 가운데 어디에 해당하는지 확인한다. 확인하면서 Parse tree 또는 Syntax tree(구문 트리)를 생성한다.
3. Semantic Analysis(의미 분석) - 의미 분석을 수행하는 단계지만 형식 언어는 의미를 가지고 있지 않기 때문에 주로 type을 검사한다.
검사한 내용을 tree에 추가해준다.
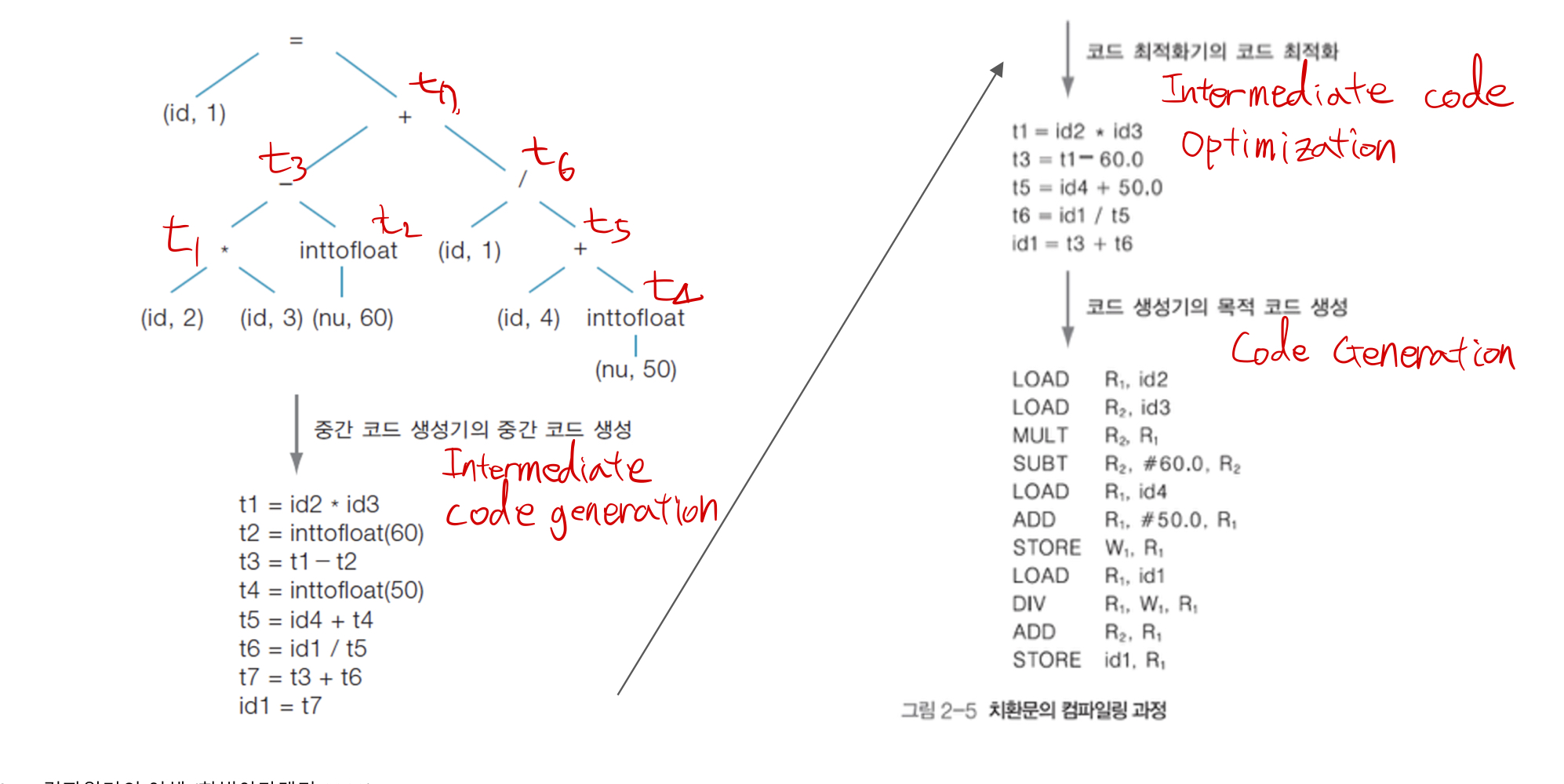
4. Intermediate Code Generation - 생성된 tree를 기반으로 intermediate code를 생성한다. target machine의 특성을 고려하지 않기 때문에, 모든 프로그래밍 언어와 target machine에 대해 각각의 compiler를 생성해야 한다는 부담이 줄어든다.

5. Intermediate Code Optimization - 코드의 실행 시간을 줄이거나 메모리 소모량을 줄이기 위해 코드 최적화를 수행한다.
Machine independent optimization(target machine의 특성에 독립적인 최적화)
Machine dependent optimization(target machine의 특성을 고려하여 최적화)로 나누어 진다.
6. Code generation - 최적화된 intermediate code를 기계어 혹은 어셈블리어로 구성된 target code(목적 코드)를 생성한다.
예시


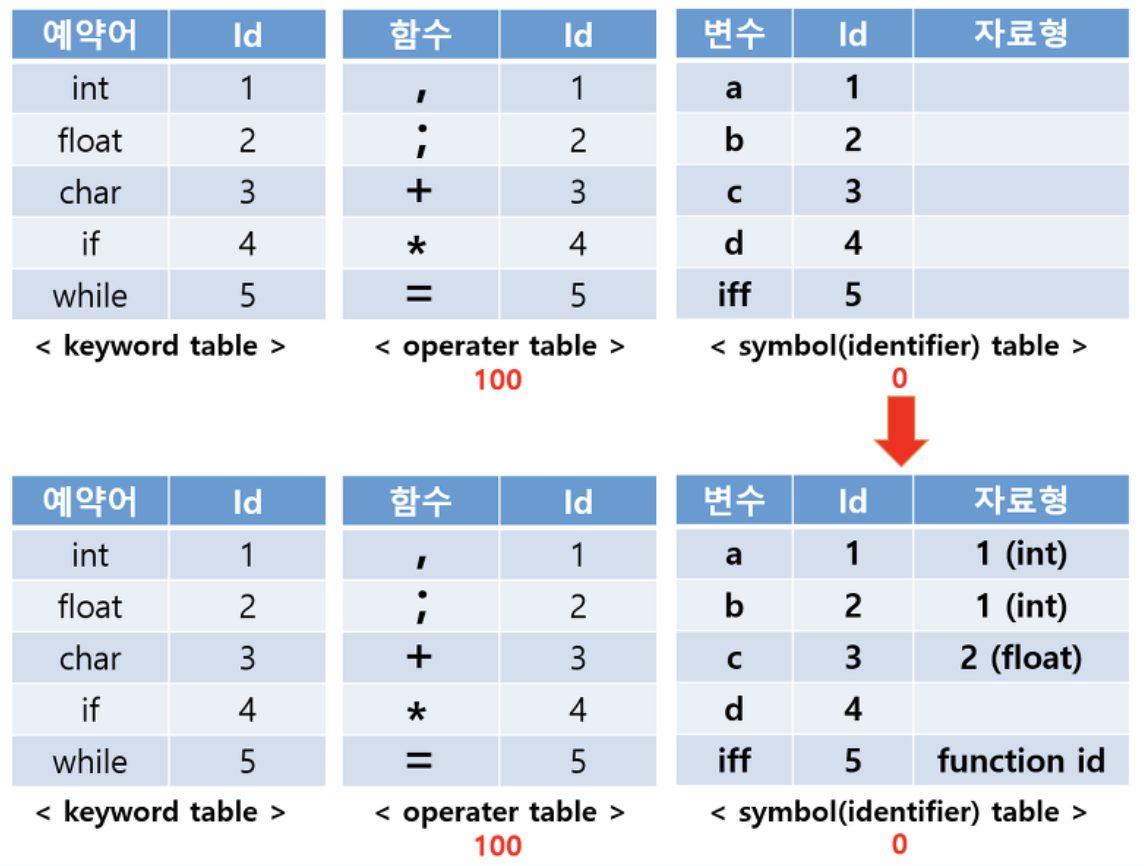
위의 예시를 Lexical Analysis 해서 table에 저장한 결과이다. 이 때, 2a를 분석하는 경우에 Lexial error가 날 것이다. d는 자료형이 없지만 이 과정에서는 에러가 나지 않는다.(5번의 경우 +를 빼줘야 한다! 잘못 만듦)
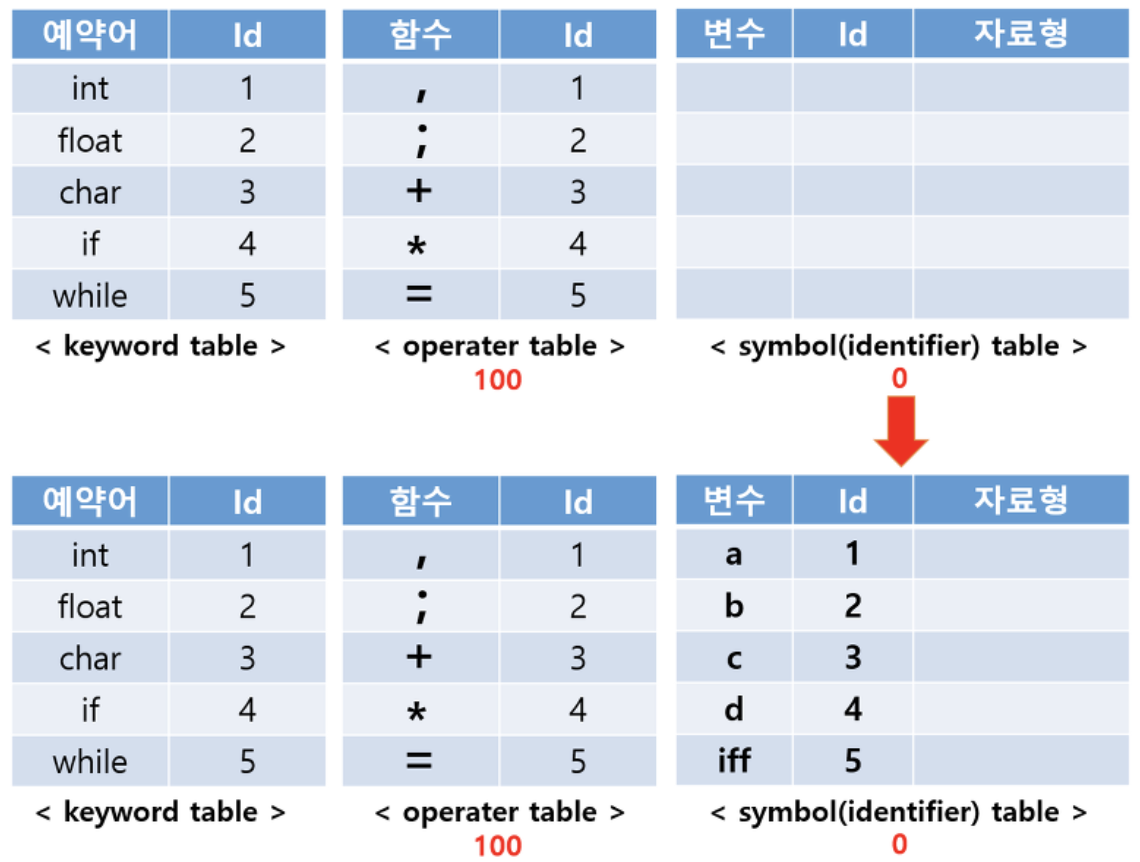
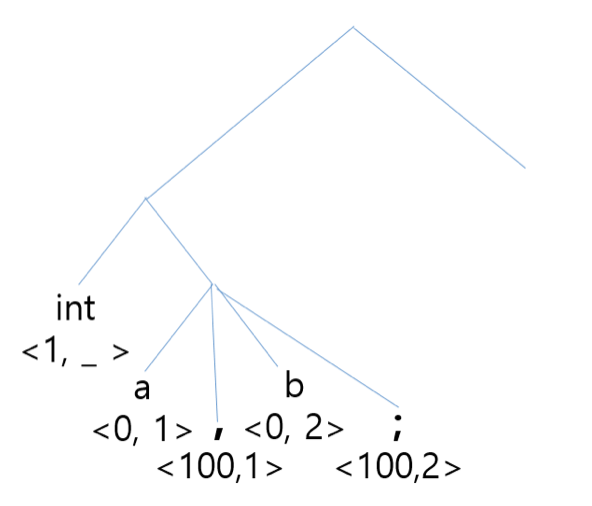
생성된 테이블을 바탕으로 tree를 만드는데 여기서 'c = b a'나 'a+b=c'와 같은 경우는 tree를 못 만들기 때문에 Syntatic Error가 발생하게 된다. tree를 parsing하면서 자료형을 symbol table에 입력한다.
컴파일러 모듈 분류 방법
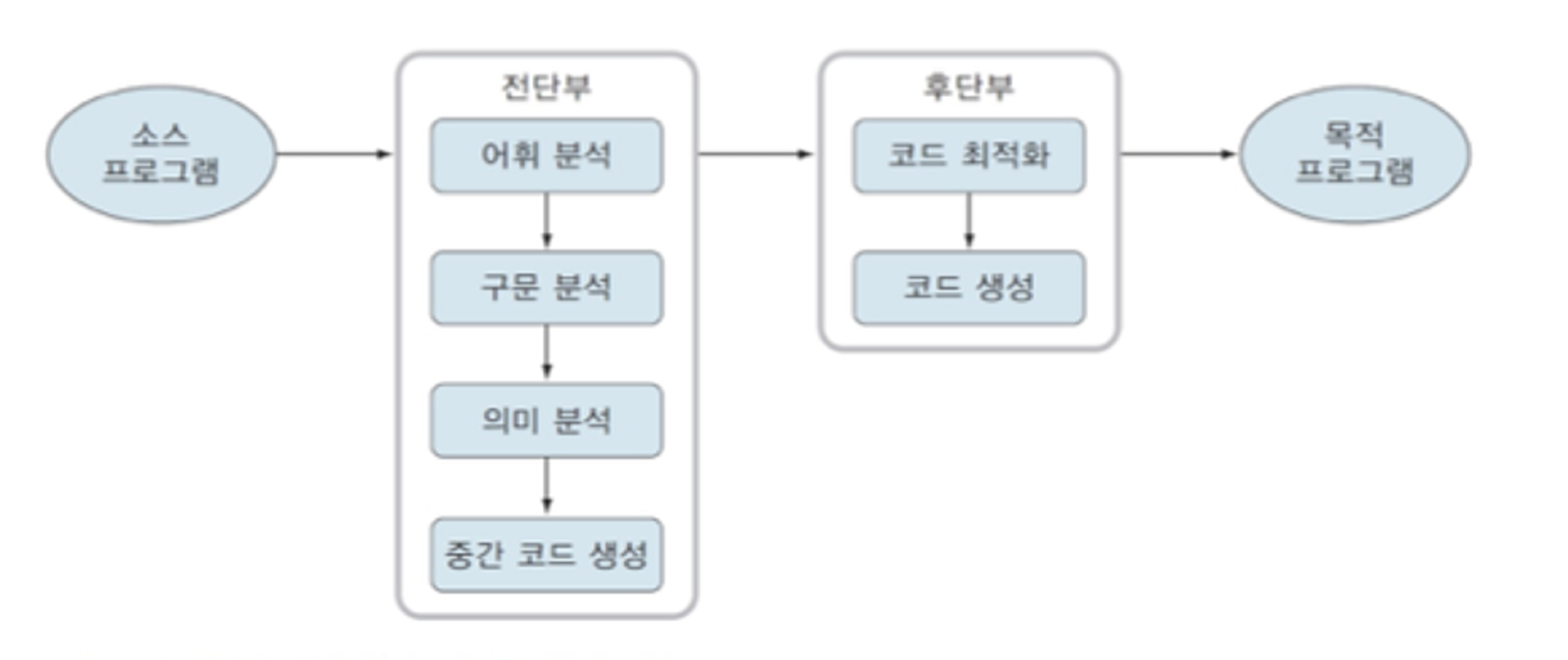
컴파일러를 위와 같이 전단보와 후단부로 나눌 수 있는데 그 기준은 machine에 independent한지(전반부) dependent한지(후반부)이다.
생성규칙에 맞는 문장인지 확인하기

ni=(po-60);는 문법에 맞는 문장일까?


맞는 문장이다 ㅋㅋ

'3-2 > 기초컴파일러' 카테고리의 다른 글
| NFA->DFA, State Minimization (0) | 2021.09.18 |
|---|---|
| Finite Automata (0) | 2021.09.18 |
| Chomsky hierarchy (0) | 2021.09.10 |
| Formal language, Formal grammar (0) | 2021.09.09 |
| Introductory Concept (0) | 2021.09.05 |